甲子園決勝では先制したチームの勝率は高いのか 母比率の検定を用いた検証
背景
野球では先制したチームの勝率は高いと報告されており、大学野球やプロ野球を対象にした調査では先制点をとったチームの勝率は約70%である。*1*2。先制点を取ることで、心理的優位に立ち、投手や守備陣が落ち着いてプレーできるという効果が影響してると考えられる。
しかし、全国高等学校野球選手権大会(以下、甲子園大会とする)は単なる競技大会にとどまらず、選手にとっては高校生活の集大成として位置づけられる特別な舞台である。そのため、試合に臨む選手の心理状態は、通常の公式戦と比較して著しく緊張度が高く、精神的負荷も大きい。特に決勝戦においては、全国的な報道や観客の熱気が加わることで、選手の心理的競技能力に大きな影響を及ぼすことが考えられる。また、甲子園大会はトーナメント形式で実施されるため、決勝戦に至るまでに複数の試合を短期間で消化する必要がある。この過程で、特に主戦投手は連投による疲労の蓄積が避けられず、試合終盤におけるパフォーマンス低下の要因となり得る。これらの心理的・身体的要因が複合的に作用することで、甲子園大会の決勝戦では試合展開が不安定化し、逆転が生じる確率が他の野球大会と比較して高くなる可能性がある。実際に、甲子園大会では「逆転劇」が数多く記録されており、その象徴的な試合として、佐賀北高校が広陵高校を逆転で下した2007年決勝戦が挙げられる。
以上より、先行研究においては先制点をチームの勝率が高いと報告されているが、甲子園の決勝では先制点を取ったチームが必ずしも勝利するとは限らないと考える。そこで本分析では、甲子園大会の決勝戦において、先制点を取ったチームの勝率が本当に高いのか、それとも勝率に有意な差がないのかを明らかにすることを目的とする。
方法
1915年から2025年までに開催された甲子園大会の決勝戦を対象とした。
データは以下のサイトから取得した。
上記のサイトより、「試合年度」「先攻チームの最初に得点したイニング」「先攻チームの最終的な得点」「後攻チームの最初に得点したイニング」「後攻チームの最終的な得点」を取得・算出した。 データの詳細は以下のCSVファイルにまとめており、GitHub上で公開している。
本分析では、甲子園大会決勝戦における「先制点を取ったチームの勝率」が、偶然による勝敗(50%)を超えて有意に高いかどうかを検証するため、比率のZ検定(proportions z-test)を用いた。帰無仮説(H₀)は「先制点を取ったチームの勝率は0.5である」、対立仮説(H₁)は「先制点を取ったチームの勝率は0.5より高い」であり、片側検定(alternative='larger')を実施した。検定には Python の統計解析ライブラリ statsmodels を用い、以下のコードにより検定統計量および p 値を算出した。
stat, p_value = sm.stats.proportions_ztest(count=COUNT, nobs=NOBS, value=0.5, alternative='larger')
ここで、
- COUNT は先制点を取ったチームの勝利数、
- NOBS は先制点を取った試合の総数、
- value=0.5 は帰無仮説における基準勝率、
- alternative='larger' は「勝率が0.5より高い」ことを検証する片側検定を意味する。
有意水準は5%とし、p値が0.05未満であれば、先制点を取ったチームの勝率が偶然の範囲を超えて高いと判断する。
分析手法の選定理由
本分析では、甲子園大会決勝戦における「先制点を取ったチームの勝率」が、偶然による勝敗(50%)を超えて有意に高いかどうかを検証するため、母比率の検定(比率のZ検定)を用いた。この検定は、ある事象(ここでは「先制したチームが勝利する」)の観測比率が、既知の基準値(母比率)と統計的に異なるかを評価するための手法である。甲子園決勝という特殊な舞台において、先制点が勝敗に影響するかどうかを検証するには、「勝率が偶然の範囲(50%)を超えて高いか」という問いに対して、母比率との比較が最も適している。また、対象となる試合数が十分に多く(n=104)、各試合が独立した事象とみなせるため、正規近似に基づくZ検定の前提条件も満たしている。このことから、母比率の検定は本分析の目的とデータ構造に対して妥当な選択であると判断した。
Z統計量の求め方
先制点を取ったチームの勝率が、帰無仮説における母比率𝑝0(ここでは 0.5)より有意に高いかを検証するため、以下のZ統計量を算出する。
ここで、
 を基準とする理由
を基準とする理由
を基準とするのは、先制点の有無が勝敗に影響しない場合、勝敗が先制点と無関係であるため、勝率は理論的に五分五分であると仮定できるためである。これに対して観測された勝率が有意に高ければ、先制点が勝敗に影響していると判断できる。帰無仮説では、「先制点の有無が勝敗に影響しない」と仮定する。つまり、先制したかどうかに関係なく、勝つ確率はランダムに決まると考える。このとき、試合の勝敗はコイン投げのような二項試行(成功 or 失敗)とみなすことができ、先制したチームが勝つ確率は理論的に 0.5(50%) になる。つまり、「先制点が勝敗に影響しないなら、勝つか負けるかは等確率である」とする。
データ加工と統計処理に用いたスクリプト
本分析におけるデータの前処理および統計検定の実施過程は、Jupyter Notebook形式で整理し、GitHub上にて公開している。具体的には、甲子園大会決勝戦における先制点と勝敗の関係について、Pythonを用いたデータ加工・比率のZ検定の実装を含む。分析の詳細は以下のリンクから確認できる。
結果
| 項目 | 値 |
|---|---|
| 対象期間 | 1915年〜2025年 |
| 決勝戦の総試合数 | 104試合 |
| 先制したチームの勝利数 | 73試合 |
| 先制時の勝率 | |
| 帰無仮説の母比率 | |
| 検定方法 | 母比率のZ検定(片側) |
| 検定統計量(Z値) | 4.501878 |
| p値 | 0.000003 |
1915年から2025年までの間に甲子園大会の決勝が実施されたのは104試合であった。先制したチームが勝利した試合は73試合(勝率約70.19%)で、帰無仮説である「p = 0.5(先制の有無と勝敗は無関係)」に対して有意に高かった(p=0.000003)。 これは、偶然にこのような偏りが生じる確率が非常に低いことを示しており、統計的に有意と判断できる。
考察
今回の分析により、甲子園大会の決勝戦においても先制点を取ったチームの勝率が約70.19%と有意に高いことが明らかになった。これは、甲子園という特殊な舞台であっても、先制点が試合の流れを左右する重要な要素であることを示唆している。この割合は大学野球やプロ野球における先行研究の結果とほぼ一致している。したがって、甲子園決勝においても先制点が勝敗に影響すると考える。
こうした統計的知見は、指導者や選手にとっても有益である。試合の戦略立案やメンタルコントロールに活用することで、勝率を高めるヒントとなり得る。甲子園という舞台の「感動」や「奇跡」を支える裏側には、こうした冷静なデータの積み重ねがあることを示すことも、本分析の意義のひとつである。
分析の課題
本分析の課題を考える。
因果関係の不明確性
本分析では、先制点と勝利の間に統計的な関連があることは示されたが、「先制したから勝った」のか、「勝つような強いチームだから先制した」のかという因果の方向性は明らかではない。 先制点は勝利の要因であると同時に、強いチームの結果として現れる可能性もあるため、因果関係を断定できない。今後は、チームの戦力指標や過去成績などを統制した上で、因果推論的なアプローチを導入することで、より精緻な理解が可能になると考えられる。先制点の定義の単純化
本分析では「最初に得点したチーム=先制」と定義しているが、得点差や得点イニングの影響は考慮していない。例えば、初回に1点を取ったがすぐに逆転された場合と、終盤に先制した場合では、試合の流れが大きく異なる。統計モデルの単純性
二項検定による単純な勝率比較にとどまっており、回帰分析や多変量解析などの高度な手法は用いていない。より精緻なモデルを用いることで、先制点の影響度を他の要因と比較しながら定量化できる可能性がある。
結論
甲子園大会の決勝戦において、先制点を取ったチームの勝率は約70.19%であり、統計的に有意に高いことが確認された(p = 0.000003)。これは、甲子園という特殊な舞台でも先制点が勝敗に影響することを示している。
サンプルサイズを増やすとどうなる?Pythonで見る大数の法則
大数の法則とは
大数の法則は母集団からサンプリングしたデータの平均(標本平均)や相対度数が、サンプリングサイズを大きくしたとき、母集団の平均(母平均)や生起確率に近づくことを保証する理論的根拠となっている定理です。シンプルな表現をすると「サンプルサイズを大きくすると標本平均は母平均に近づく」です。注意が必要なのは、必ずしもサンプルサイズが大きいほうが母平均に近いとは言い切れないことです。大数の法則は、「サンプルサイズを無限に大きくすれば、標本平均は確率的に母平均に収束する」であり、ポイントは「確率的に」と「無限に」という言葉です。「確率的に収束する」ということの意味は、「サンプルサイズが大きくなればなるほど、標本平均が母平均から大きく外れる確率がゼロに近づく」という意味です。これは「常に」標本平均が母平均に近くなることを保証するものではありません。サンプルサイズが小さい場合は特に、個々のサンプリング結果は変動します。
大数の法則は何が嬉しいか
標本から母集団を推測できる
母平均を調べるためには「母集団全体」を調べる必要があります。しかし、現実的には「コストや時間が膨大になる」「母集団が変動する」といった理由から母集団全体を調べることは少ないです。また、全数調査を実施した場合でもアンケートでは無回答などから「母集団全体」を調べられないことがあります。このような「母集団全体」を調べられないときに大数の法則が役に立ちます。母集団から標本をサンプリングして調査することを標本調査と言い、サンプルサイズが大きくすることで標本平均は確率的に母平均に収束することが大数の法則によって保障されています。これによって「一部を調べれば全体を推測する」ことが可能になるのです。
データが安定して信頼できる
サンプルサイズが小さいとデータがばらつきやすく、「運が悪かっただけなのか本当にそうなのか」がわかりません。しかしサンプルサイズを大きくすると結果は理論的な値に近づいていきます。 例えばコインを10回投げると7回表が出ることもありますが、1万回投げれば大体表が出る割合が50%前後に落ち着きます。
Pythonで大数の法則を確認する
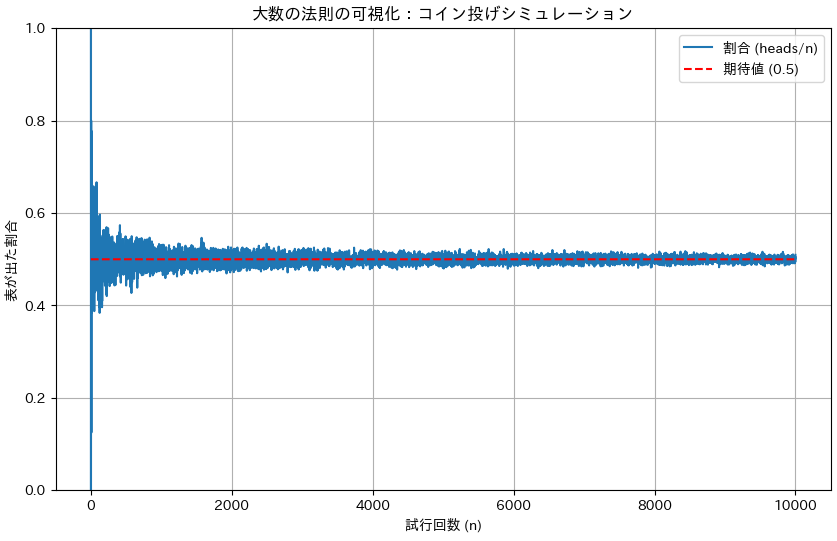
以下のスクリプトは、コイン投げの試行回数を増やしていくにつれて、表が出る割合が理論値(0.5)に近づいていく様子をグラフで示します。
import numpy as np import matplotlib.pyplot as plt # matplotlibで日本語のフォントを使用するためにimport import japanize_matplotlib # 試行回数(最大値) max_trials = 10000 # 試行回数ごとの表が出た割合を格納するリスト proportions = [] # コイン投げシミュレーション # 試行回数を増やしながら、表が出た割合を計算 for n in range(1, max_trials + 1): # n回コインを投げるシミュレーション (1: 表, 0: 裏) flips = np.random.choice([0, 1], n) # 表が出た回数を計算 heads = np.sum(flips) # 表が出た割合を計算してリストに追加 proportions.append(heads / n) # グラフの描画 plt.figure(figsize=(10, 6)) # 試行回数ごとの表の割合をプロット plt.plot(range(1, max_trials + 1), proportions, label='割合 (heads/n)') # 理論上の期待値(0.5)を直線で描画 plt.plot(range(1, max_trials + 1), [0.5] * max_trials, 'r--', label='期待値 (0.5)') # グラフの設定 plt.title('大数の法則の可視化:コイン投げシミュレーション') plt.xlabel('試行回数 (n)') plt.ylabel('表が出た割合') plt.ylim(0, 1) plt.legend() plt.grid(True) plt.show()
 ■参考:numpy.random.choice — NumPy v2.1 Manual
■参考:numpy.random.choice — NumPy v2.1 Manual
サンプルサイズ小さいときはばらつきが大きくなっていますが、サンプルサイズが大きくなるにつれて、理論値の0.5に近づくのがわかると思います。
特定の分布は仮定していない
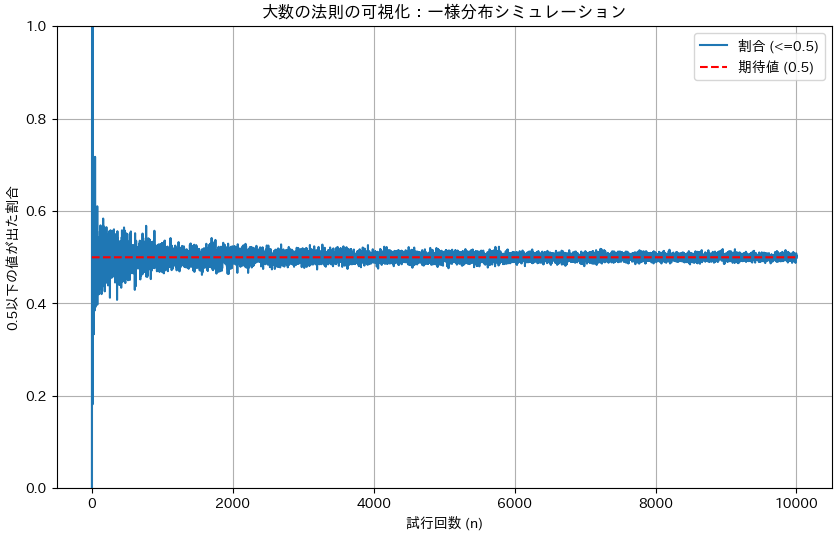
大数の法則は同じ条件で独立にデータを集めて平均が定義できることを仮定していますが、特定の分布を仮定していません。 二項分布や正規分布はもちろん、一様分布やポアソン分布でも問題ありません。
試しに一様分布でも大数の法則が見れるかを確認してみます。
# 試行回数(最大値) max_trials = 10000 # 試行回数ごとの0.5以下の値が出た割合を格納するリスト uniform_proportions = [] # 一様分布シミュレーション # 試行回数を増やしながら、0.5以下の値が出た割合を計算 for n in range(1, max_trials + 1): # n個の一様乱数を生成 (0から1まで) uniform_samples = np.random.uniform(0, 1, n) # 0.5以下の値が出た回数を計算 count_below_0_5 = np.sum(uniform_samples <= 0.5) # 0.5以下の値が出た割合を計算してリストに追加 uniform_proportions.append(count_below_0_5 / n) # グラフの描画 plt.figure(figsize=(10, 6)) # 試行回数ごとの0.5以下の値の割合をプロット plt.plot(range(1, max_trials + 1), uniform_proportions, label='割合 (<=0.5)') # 理論上の期待値(0.5)を直線で描画 plt.plot(range(1, max_trials + 1), [0.5] * max_trials, 'r--', label='期待値 (0.5)') # グラフの設定 plt.title('大数の法則の可視化:一様分布シミュレーション') plt.xlabel('試行回数 (n)') plt.ylabel('0.5以下の値が出た割合') plt.ylim(0, 1) plt.legend() plt.grid(True) plt.show()
 ■参考:numpy.random.uniform — NumPy v2.2 Manual
■参考:numpy.random.uniform — NumPy v2.2 Manual
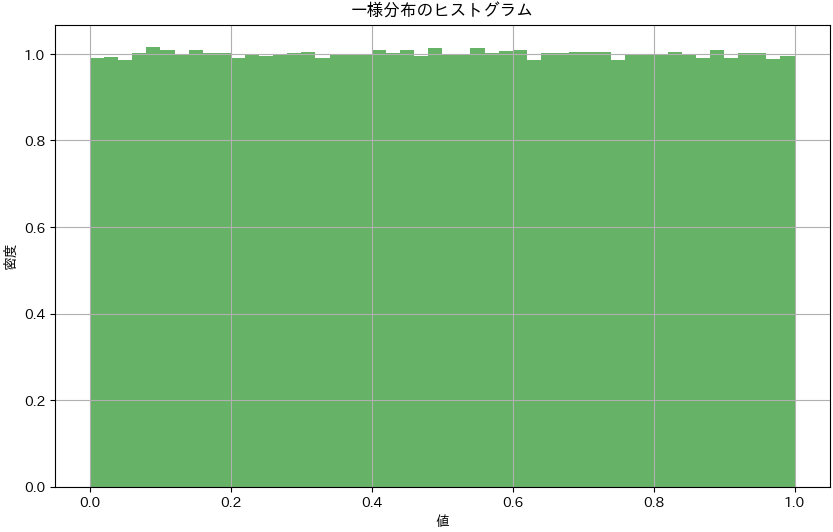
念のために一様分布であることの確認をしておきます。
# 大量のサンプルを生成 num_samples = 1000000 uniform_samples = np.random.uniform(0, 1, num_samples) # ヒストグラムの描画 plt.figure(figsize=(10, 6)) plt.hist(uniform_samples, bins=50, density=True, alpha=0.6, color='g') # グラフの設定 plt.title('一様分布のヒストグラム') plt.xlabel('値') plt.ylabel('密度') plt.grid(True) plt.show()
データ分析に対する批判的な考え方
目的
データ分析に対する批判的な考え方をまとめる。自分で行っているデータ分析がより良いものにするためにセルフレビューや自分がレビュー者になったときに参考にすることを目的とする。
読者対象
- データ分析を依頼する人
- データ分析者
データ分析に対する批判的な考え方
- 着眼点に対する批判
- 仮説に対する批判
- データに対する批判
- データの取得方法に対する批判
- アンケートとか
- バイアス
- 目的や明らかにしたいことに対する代表的なデータと言えるか
- 比較対象は合っているか
- データの取得方法に対する批判
- 分析手法に対する批判
- 仮定を満たして良いと判断して良い根拠はあるのか
- 結果に対する批判
- サンプルサイズ
- 解釈に対する批判
- 結論に対する批判
データ分析する前に考えること
目的
データ分析する前に考えることをまとめる
読者対象
- データ分析を依頼する人
- データ分析者
データ分析する前に考えること
- 問題を整理する
- あるべき姿とのギャップ
- 課題を整理する
- 問題を解決していくために具体的に取り組むべきこと
- データ分析の対象が施策であれば、その施策の目的・目標
- どのような意思決定をしたいのかを整理する
- 「知りたい」ではなく、知ったあとどのような意思決定をするのかを整理する
- 分析によってなぜ意思決定を支援できるのかを考える
- 分析の目的を整理する
- 仮説を考える
- 仮説の元になるものは事実や検証された結果にする
- 仮説の根拠の蓋然性は高いか
- 仮説の上に仮説を重ねない
- 根拠が事実ではなく仮説のものがあれば先にその仮説を検証する
- 検証した結果,仮説が支持される結果を得られてから次の仮説を立てる
- 特に分析依頼を受けたときは要注意
- 着眼点を整理する
- 問題解決のための着眼点を整理する
- なぜその着眼点で分析すると問題解決につながると考えたのか
- 仮説を支持する結果は何かを考える
- 仮説を支持する結果を得るためにはどんな分析設計をすれば良いかを考える
自分は何を提供しているのかを考えておいたほうがよさそう。要件のとおりデータ抽出をするのも立派な仕事ではある。しかし、データを抽出するだけでは意思決定の支援・課題解決につながる分析・業務貢献は難しいことが多い。課題・問題を定義し、解決ためのアクションや意思決定に必要な分析・結果は何かを考えることで価値のあるデータ分析ができると考える。
「午前中の涼しいうち」はまだ存在するのか?
緒言
XのTLに下記のポストが流れてきた。
「昔は午前中に涼しい時間帯があり正午から午後にかけて暑かったが、最近は午前中に涼しい時間帯はなく午前から午後までずっと暑い」という意味かもしれない。反応を見ると概ね賛同しているような感じ。まぁXなのでいいねもらえそうな表現として「死語」としていると思うが、果たして実際どうなんだろうと気になった。実際に死語になったのかというよりも、午前中に涼しい時間帯というのはなくなったのだろうか。まだ午前中の涼しい時間帯があるとしたらどの時間帯なのか。「午前中の涼しいうち」がなくなっているのであれば問題である。「午前中の涼しいうち」があればその涼しいうちに家事や買い物などの用事を済ませて、暑くなったらクーラーのきいた部屋でダラダラできるが、午前中から午後までずっと暑ければそれができなくなるので、今までの戦略(午前中の涼しいうちに済ませる)とは別の戦略を考える必要が出てくる。死んでしまった日本語
— 赤すぐり❦ (@aka_suguri) 2024年7月22日
「午前中の涼しいうちに」
そこで今回は午前中の涼しい時間帯が無くなっているか、もし涼しい時間帯が残っているならばどの時間帯なのかを分析した。
分析
言葉の定義
午前中:07:00 - 12:00
涼しい:28℃未満
データソース
気象庁:https://www.data.jma.go.jp/stats/etrn/index.php
1時間ごとにデータを取得
対象
地点:東京
西暦:2010 - 2024年
月 :7月
日 :1 - 31日
時間︰07:00 - 16:00
方法
各年ごとに28℃未満の時間帯(hour)日数をカウントした。7月を対象としているため最大31日となる。
例えば、2010年の7時台が28℃未満の日数は23日といった感じ。
結果と考察と所感
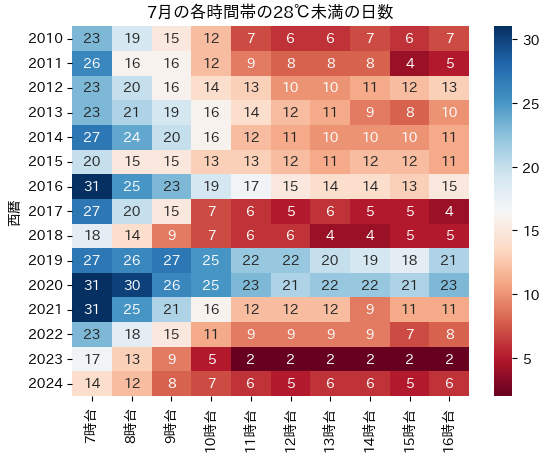
表の数字は28℃未満の日数を表す。
2019年と2020年がやたら28℃未満の日が多い気がする。2010年から集計したが、両年だけ28℃未満の時間帯の日数が多い。
2018年・2023年・2024年は9時台の時点で28℃未満の日数が2桁に届いていない。これらの年は雑な計算だが、9時台に28℃未満となるのは3日に1日程度であり、9時台はすでに「涼しいうち」ではないと考えられる。2024年に限って言えば、7時台の時点で2日に1日は28℃を超えているため涼しくない。基本的に午前中は気温が上がるため、朝起きた時点で涼しくない日が7月は半分もある。確かに涼しい日が少ない感じはする。
とはいえ、午前中に28℃未満の日が1日もないという月は今のところ存在していない。また、2024年でも8時台が28℃未満の日数は2桁はある。そのため、今回の定義における「午前中の涼しいうち」はなくなったわけではないと考える。ただし、時間帯は限定的で9時台になると個人的にはほとんどの日で涼しくないと感じる。 涼しい時間帯がかなり限定的なので、今までの戦略(午前中の涼しいうちに済ませる)とは別の戦略を考えたほうがよさそう。
注意点
今回は直接「午前中の涼しいうちに」という言葉が使われなくなったのかは調べていませんのでその点ご注意ください。
きっと2024年の8月も午前中から暑い日が続くと思うので、皆様熱中症にはお気を付けください!
日本プロ野球の2番打者について主成分分析を用いてタイプ分けした
背景
メジャーリーグでは2番にパワーヒッターを置くのはよく知られているように思う。2023年の打者大谷さんはエンゼルスで一番多かったスタメンの打順は2番だった。ホームラン王となる打者が最も多いスタメンの打順が2番だったのである。2番打者にパワーヒッターを置く理由としては、3番と比較して2番は年間70打席ほど多いため(『The Book』という書籍がはじめらしい)。打席が多い打者が長打や本塁打を打つとたくさん取れるから確かに2番にパワーヒッターを置くのは良いかもしれない。そういった流れを受けてか、日本プロ野球でも2番にパワーヒッターを置く流れがある。かつて2番打者に求められるものといえば、バントや進塁打などで出塁した1番打者を進塁させる繋ぎ役といった印象があるが実際どうなんだろうか。日本プロ野球ではスタメンの2番にどんなタイプを置いているのか、パワーヒッターをスタメンの2番に置いている試合はどれくらいあるのか。また球団によって違いはあるのかといったことが気になってくる。例えば、ある球団はスタメンの2番に繋ぎ役を置くことが多いが、他方、別の球団ではパワーヒッターを置くことが多いなど。そこで、主成分分析という分析手法を用いて選手をタイプ分けして、日本プロ野球の2番打者がどのようなタイプが多いのかを集計した。また、球団によって違いがあるのかも見たいので球団別でも集計した。
分析
分析対象は2023年の日本プロ野球の打者としての成績
分析に用いた元のデータ
打者としての成績は日本プロ野球の公式ホームページから手作業でデータを取得
打順データはプロ野球データFreakより取得
分析の対象選手
全選手680名のうち、打席数が200以上の124名が分析対象
分析対象の打者の成績
出塁率・一塁打率・本塁打率・犠打率・盗塁数・四球率の6つの変数とした。率にしたのは打席数による影響を減らすため(本当は盗塁も率にしたかったが適切な定義が難しく断念)。なぜ、6つの変数にしたのかは主成分分析をいくつかのパターンで試した結果いい感じになったのがこの6つの組み合わせだったためです。まぁ趣味の分析だから。
分析手法
上記の変数を標準化して主成分分析を実施。計算や可視化はPythonを用いた。各主成分の主成分負荷量からその主成分のタイプを定義した。各選手の主成分得点を算出したあと、主成分得点が最も高い主成分をその選手のタイプ(主成分)とした。
結果と解釈とコメント
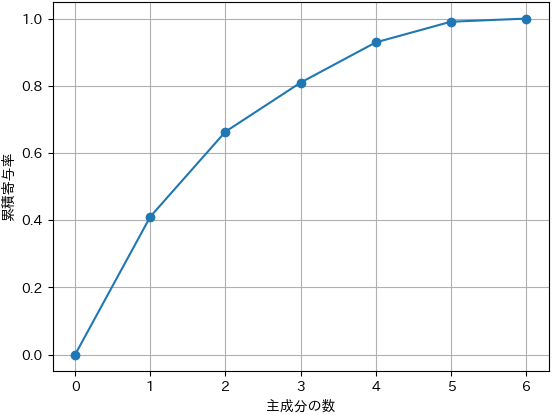
累積寄与率
3次元で約80%を超えるので、3次元に圧縮することにしました。
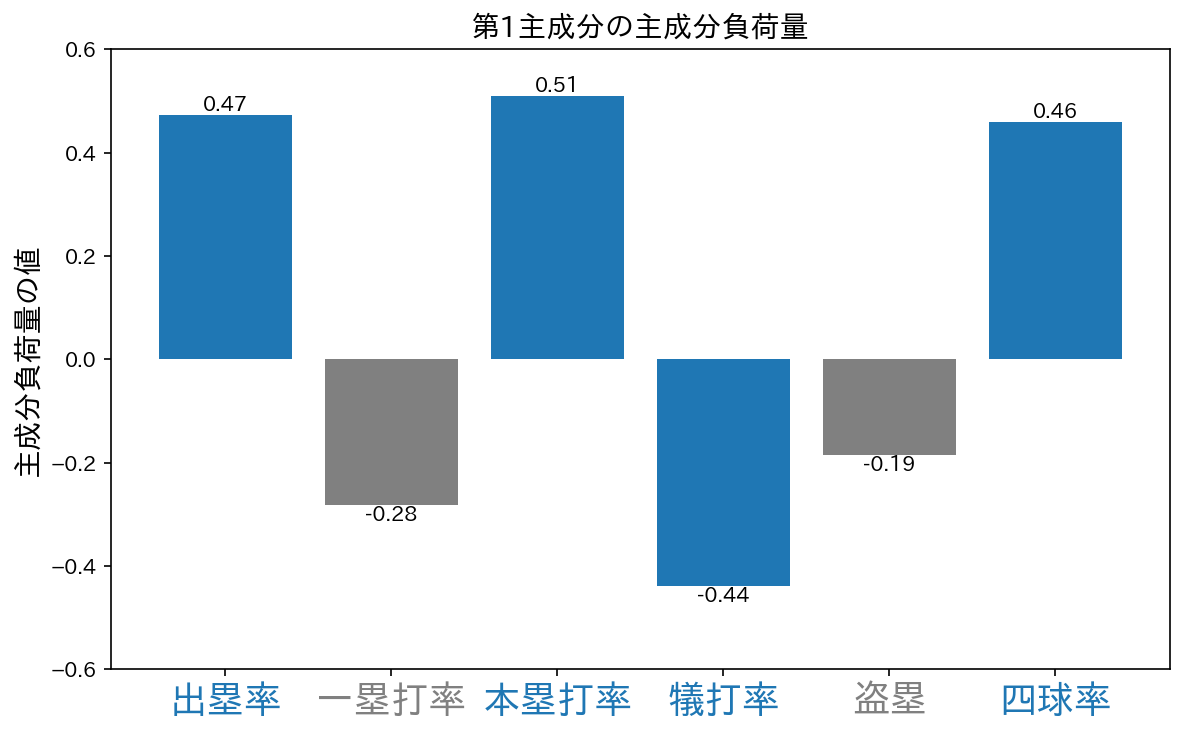
各主成分の主成分得点からタイプを定義する
第1主成分
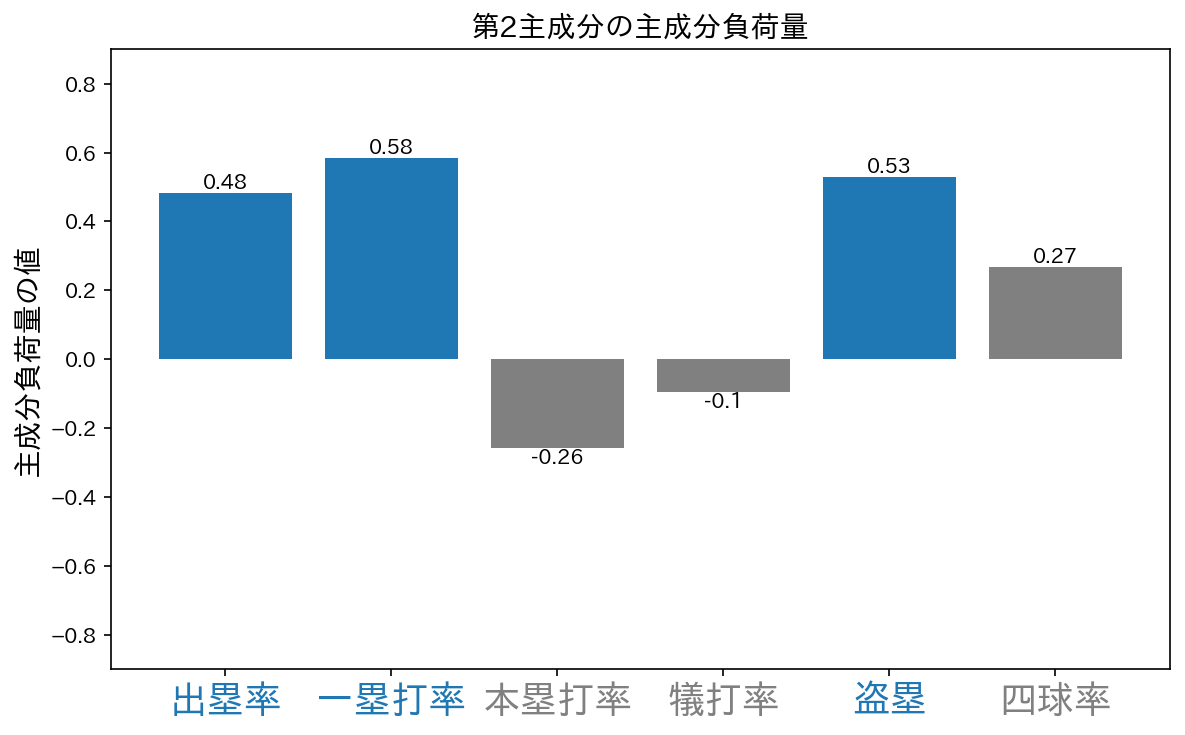
第2主成分
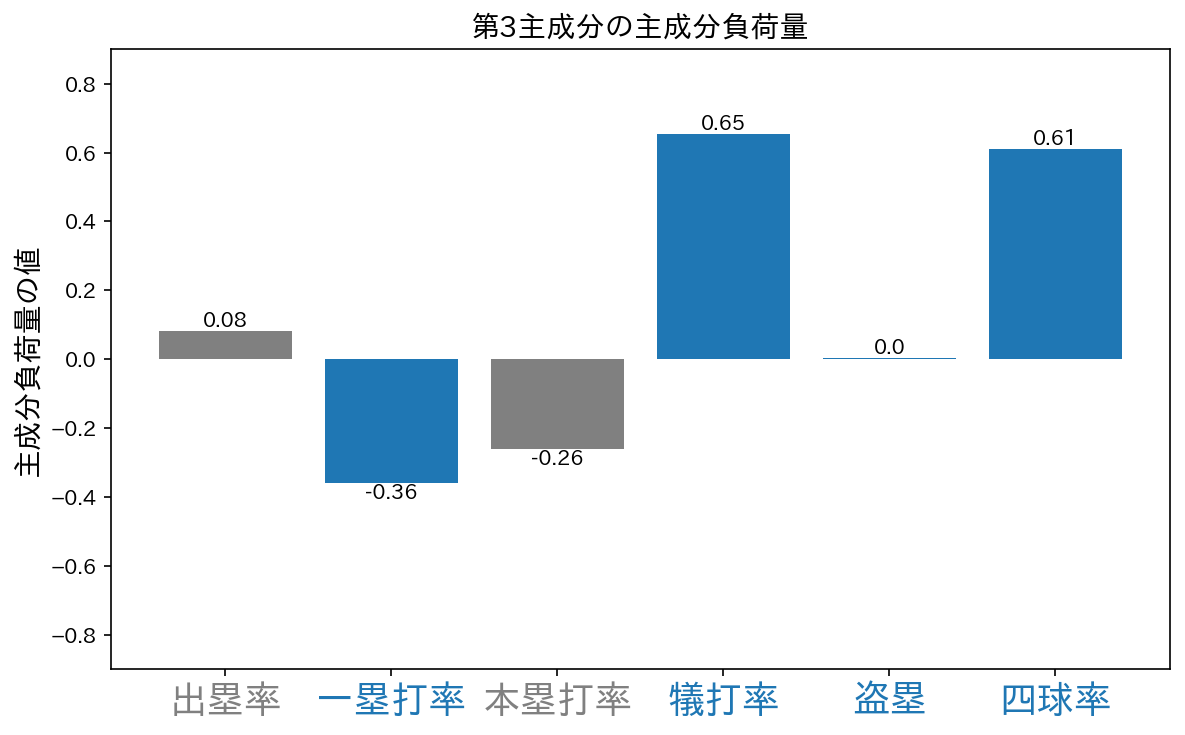
第3主成分
各選手の主成分得点とタイプ分けを確認
5選手を代表にどのようにタイプ分けがされるかを確認する
| 選手名 | 第1主成分 | 第2主成分 | 第3主成分 | 選手タイプ | 出塁率 | 一塁打率 | 本塁打率 | 犠打率 | 盗塁 | 四球率 |
|---|---|---|---|---|---|---|---|---|---|---|
| 今宮健太 | -1.436662 | -0.688291 | 0.53285 | 繋ぎ役 | 0.28719 | 0.161157 | 0.018595 | 0.049587 | 4 | 0.055785 |
| 甲斐拓也 | -0.58762 | -2.306767 | 1.165709 | 繋ぎ役 | 0.257143 | 0.111905 | 0.02381 | 0.042857 | 0 | 0.07381 |
| 川瀬晃 | -3.233958 | -1.314095 | 1.814664 | 繋ぎ役 | 0.259615 | 0.153846 | 0 | 0.086538 | 2 | 0.043269 |
| 栗原陵矢 | 0.72874 | -1.036991 | -0.691032 | パワーヒッター | 0.299742 | 0.147287 | 0.033592 | 0.002584 | 0 | 0.072351 |
| 近藤健介 | 4.293725 | 1.724899 | 1.516016 | パワーヒッター | 0.442088 | 0.146819 | 0.042414 | 0 | 3 | 0.177814 |
今宮選手・甲斐選手・川瀬選手は第3主成分得点が最も高いので繋ぎ役、栗原選手・近藤選手は第1主成分得点が高いのでパワーヒッター、といった感じで主成分得点が最も高いものをその選手の主成分として上記のタイプの定義に紐づけていく
タイプに偏りがないか確認
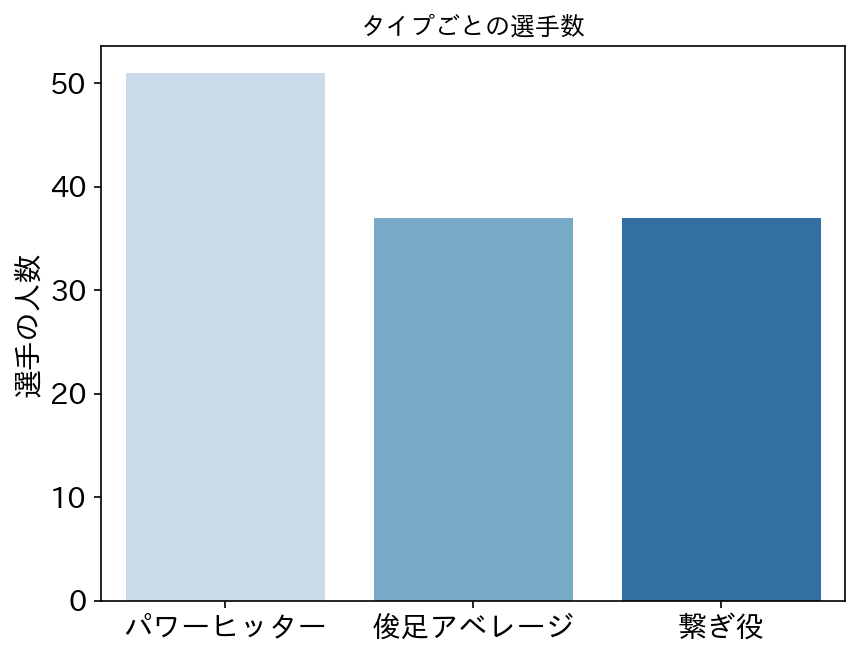 パワーヒッターが少し多いが、まぁ大体同じとする
パワーヒッターが少し多いが、まぁ大体同じとする
日本プロ野球全体のタイプ別2番のスタメン数
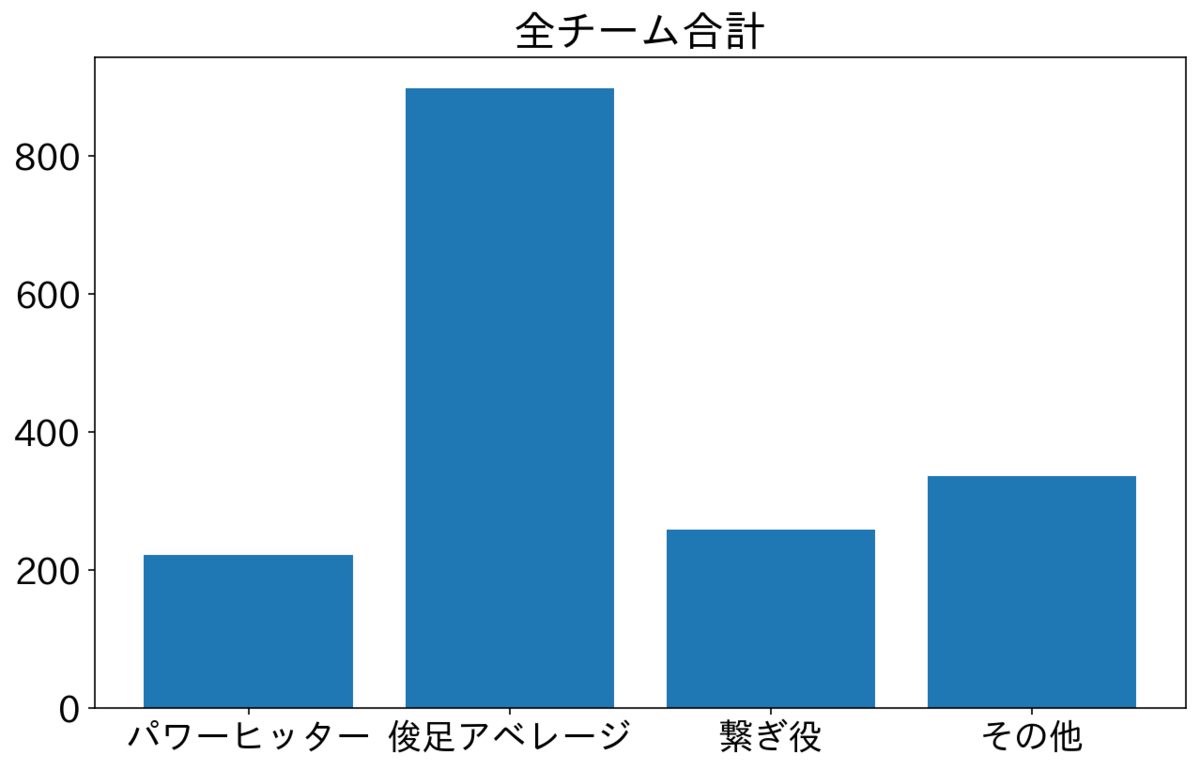 日本プロ野球全体でみると圧倒的に俊足アベレージタイプが多い。次いで繋ぎ役。僅差でパワーヒッター。ちなみにその他は打席数が200未満の選手がスタメンだった数を示す。
日本プロ野球全体でみると圧倒的に俊足アベレージタイプが多い。次いで繋ぎ役。僅差でパワーヒッター。ちなみにその他は打席数が200未満の選手がスタメンだった数を示す。
圧倒的に俊足アベレージが多いですね。繋ぎ役とパワーヒッターを置くのは少ない。バントがうまくとにかく出塁した1番打者を次の塁に進塁させることが2番の役割なんて考えもあるが、今回の分析ではそういったタイプを2番に置くことは少ないと考えるのが妥当そうな感じ。今回は2023年だけのデータだったので、昔と比べてどうかは分析からは言えないが、もしかしたら役割が変わってきているかもしれない。バントは得点の機会を減らすなんて言われることもあるらしいので、そういったバントによる得点への影響が明らかになって事でバントそのものをしなくなったのかも。
日本は2番打者に俊足アベレージタイプを置くことが多いが、メジャーと比べてどうなのかも気になってくる。やっぱり、パワーヒッターを置くことが多いのか、それとも日本と同じように俊足アベレージを置くことが多いのか。あと気になるのは、日本で俊足アベレージ・繋ぎ役・パワーヒッターのどのタイプを置くと点が入りやすいのか。これを明らかにするためには、相手投手・選手の能力と調子・前後の打者・試合の流れなど影響する要因はいくつかありそうなので、それらのデータと因果推論の手法を使う必要はありそう。一番の問題は影響する要因を整理するのとデータを集めるところか。
各チームのタイプ別2番スタメン数
セ・リーグ
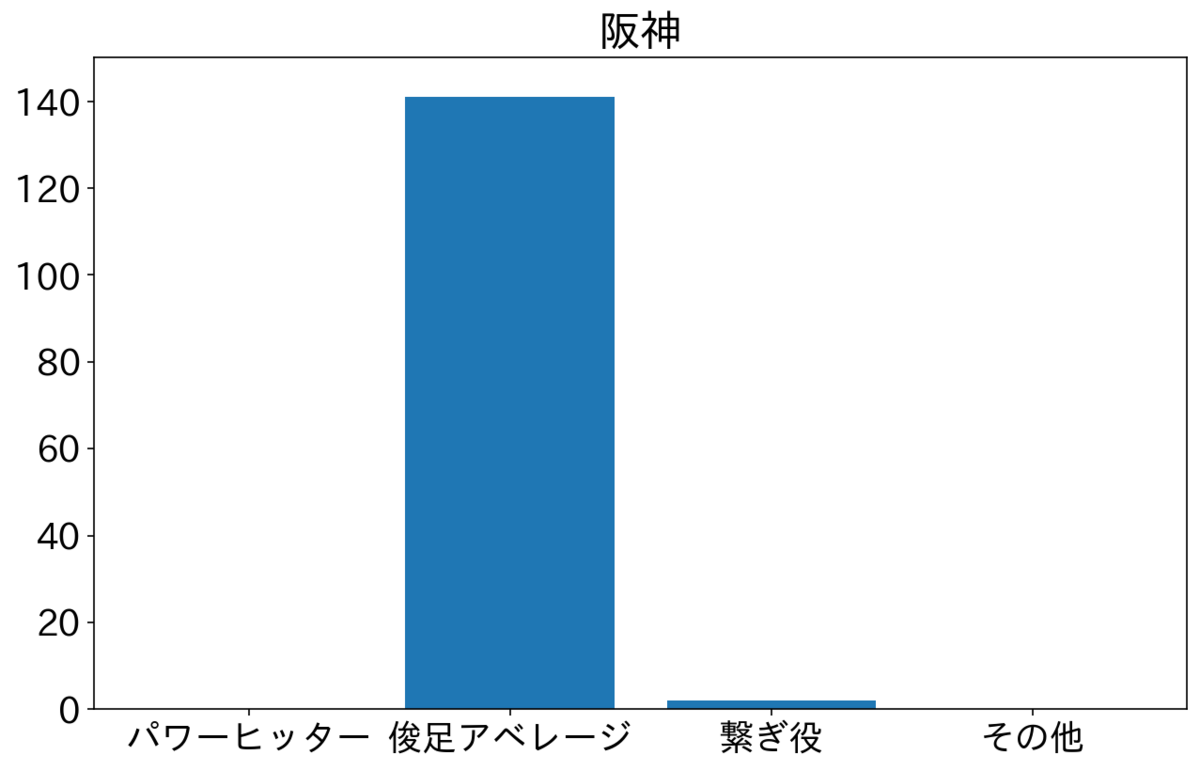
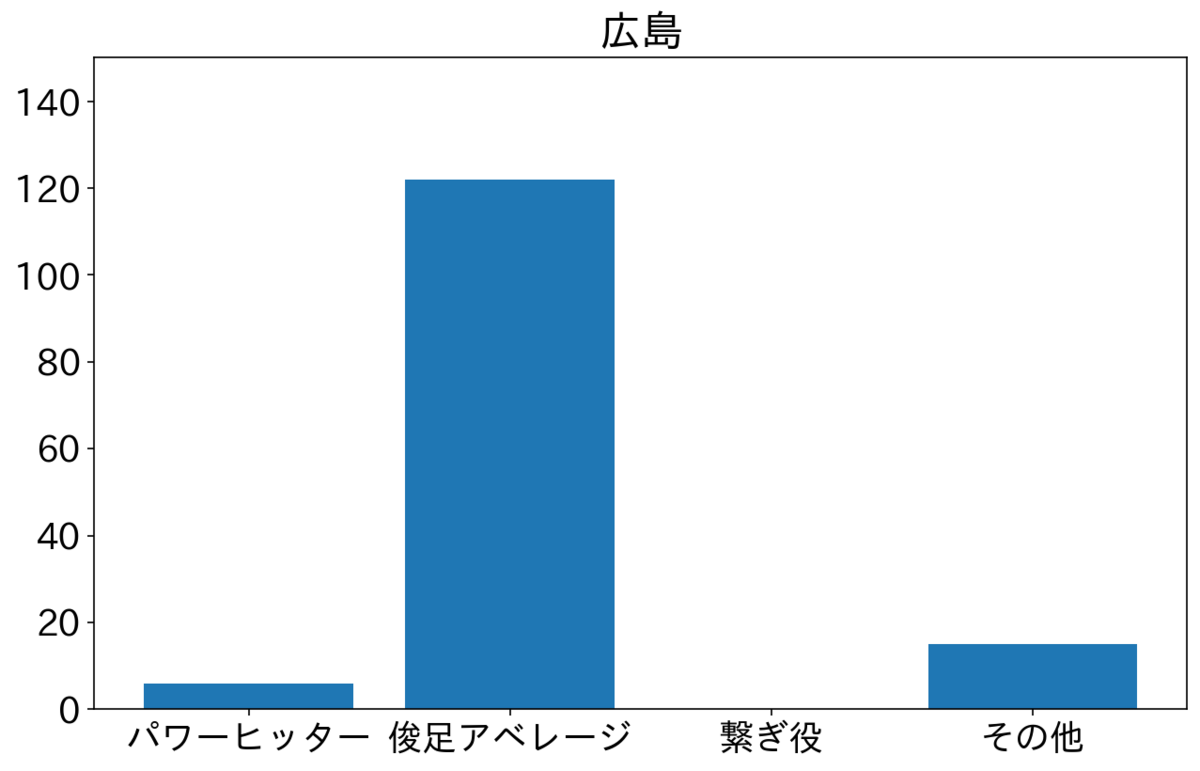
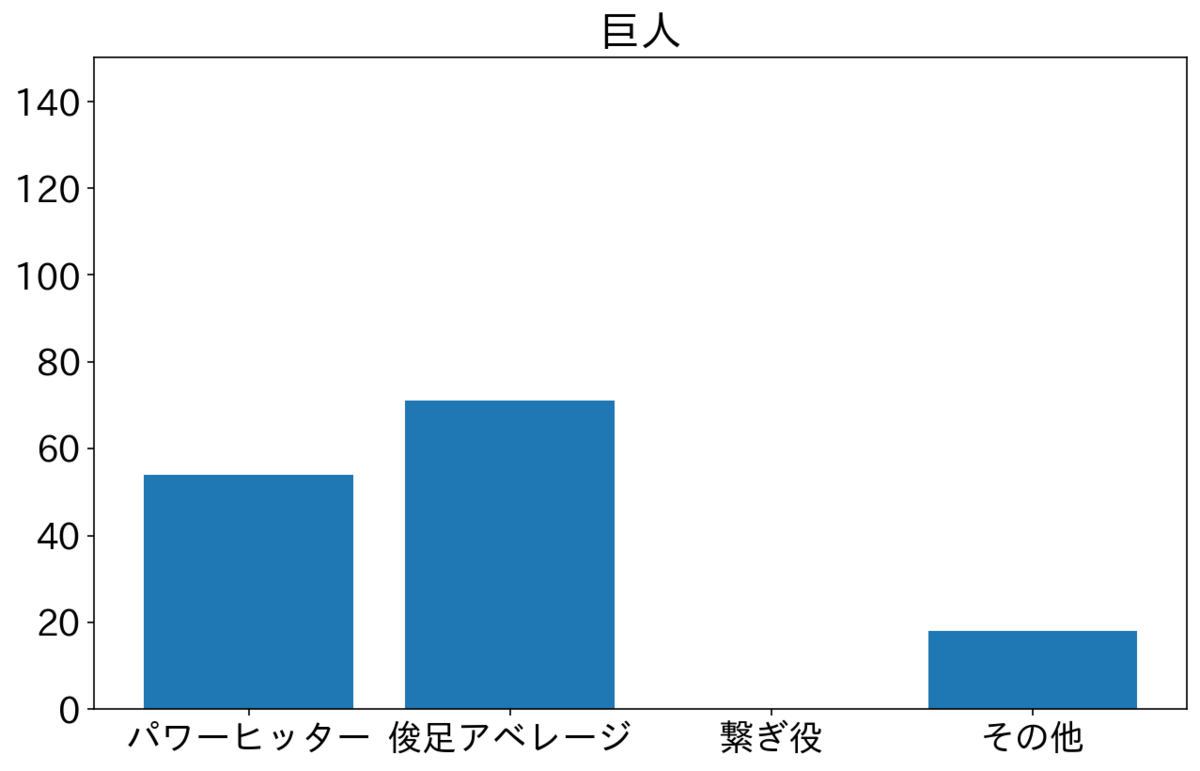
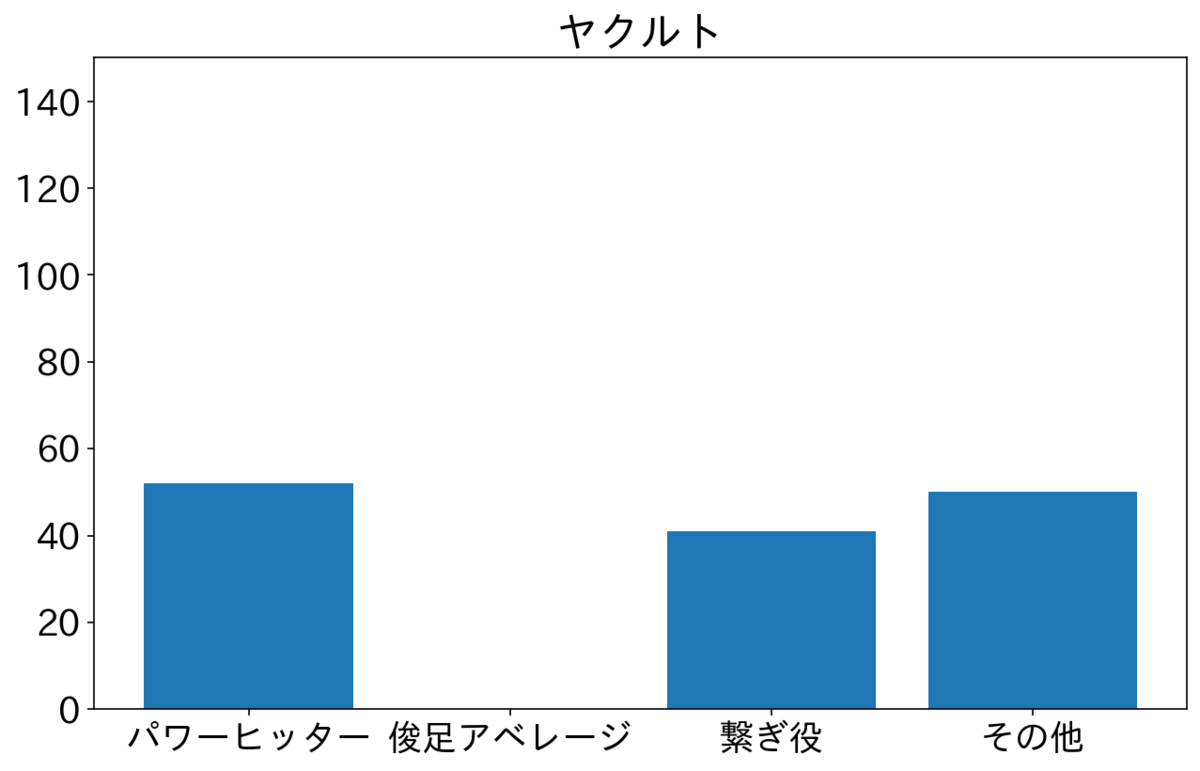
阪神と広島はずっと2番がそれぞれ中野選手・野間選手でタイプが俊足アベレージのため、俊足アベレージが突出している。それぞれシーズンを1位と2位で終えた。他の球団と比較するとパワーヒッターを多めにおいているのが巨人とヤクルトで、それぞれ4位と5位で終えた。これだけ見ると2番にパワーヒッター置くよりも俊足アベレージ置いたほうがよさそうだけど、順位にはほかの要因も影響するのであまり言及はできない。
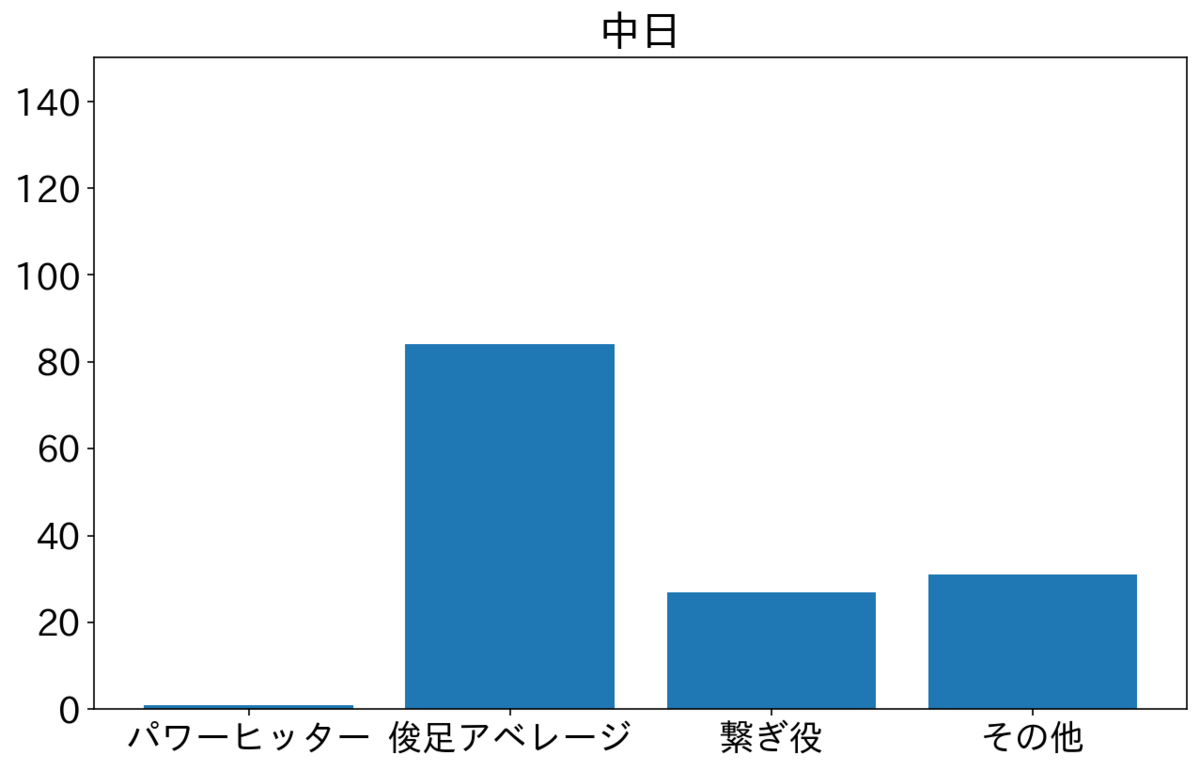
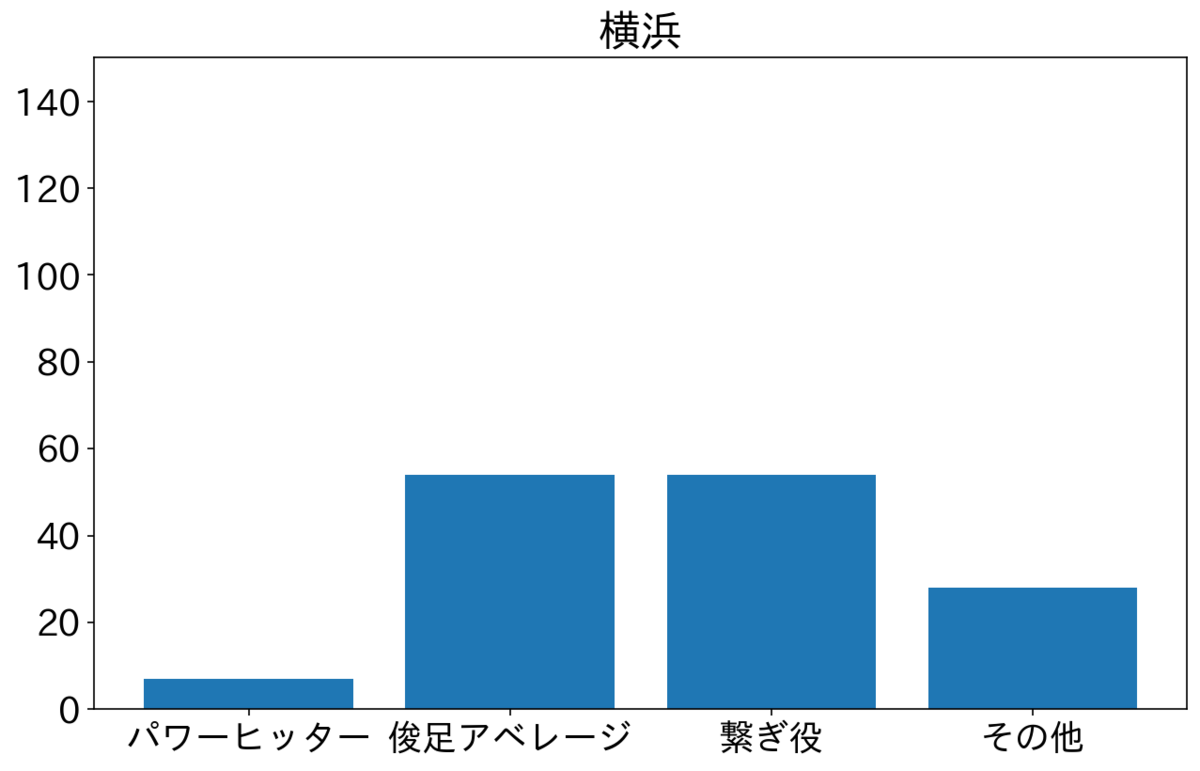
中日も多いのは俊足アベレージだから、ほかの要因もあるのは想像に難くない。横浜は俊足アベレージと繋ぎ役が半分くらいで、ほかの球団と比べると繋ぎ役多め。
セ・リーグ
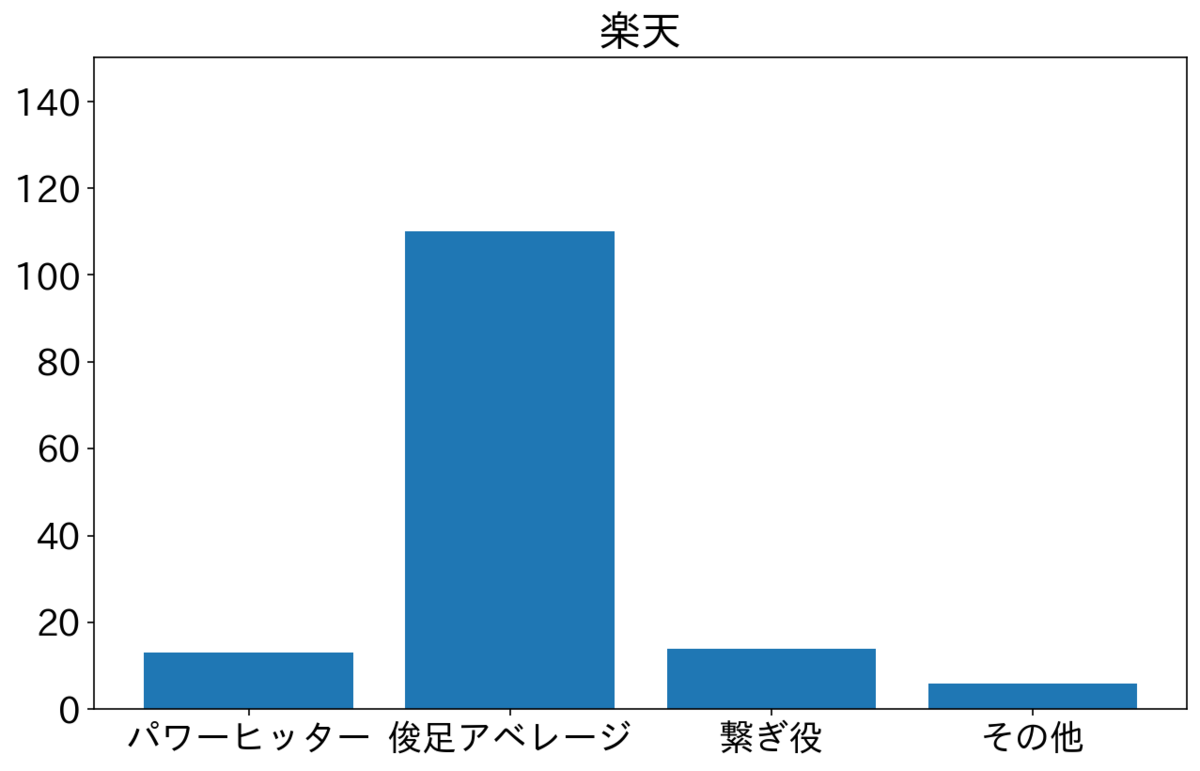
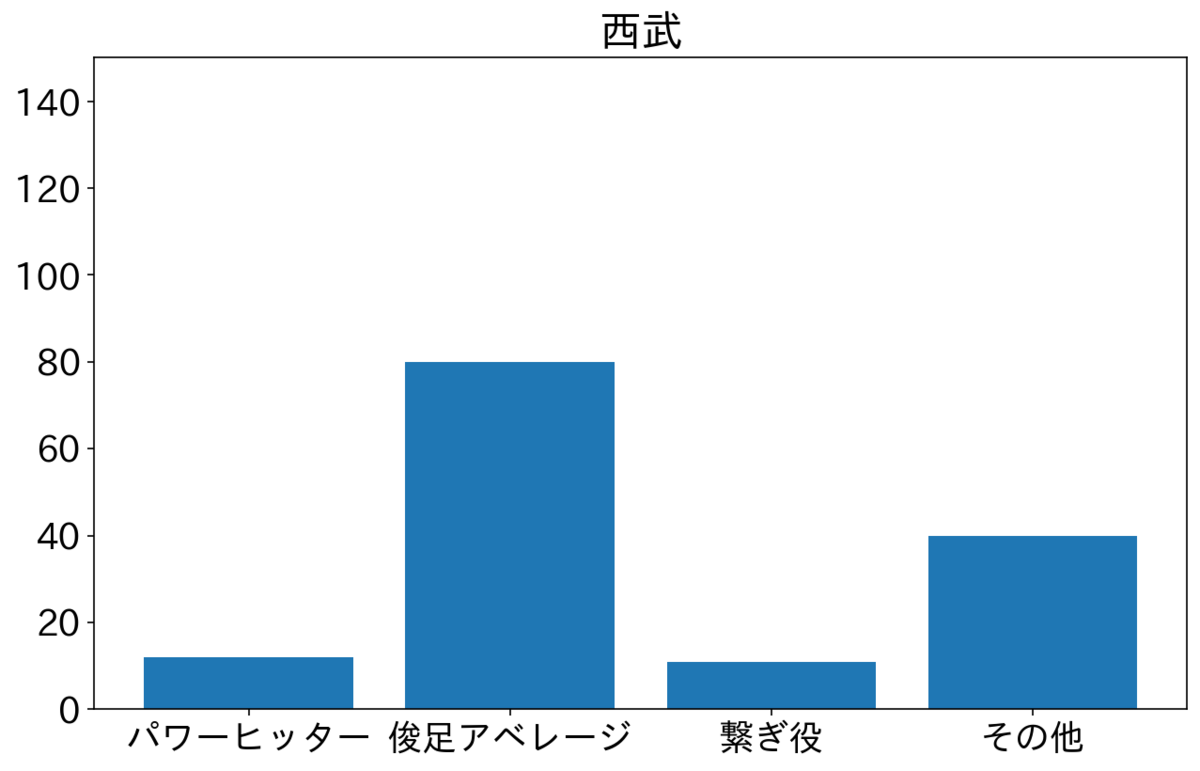
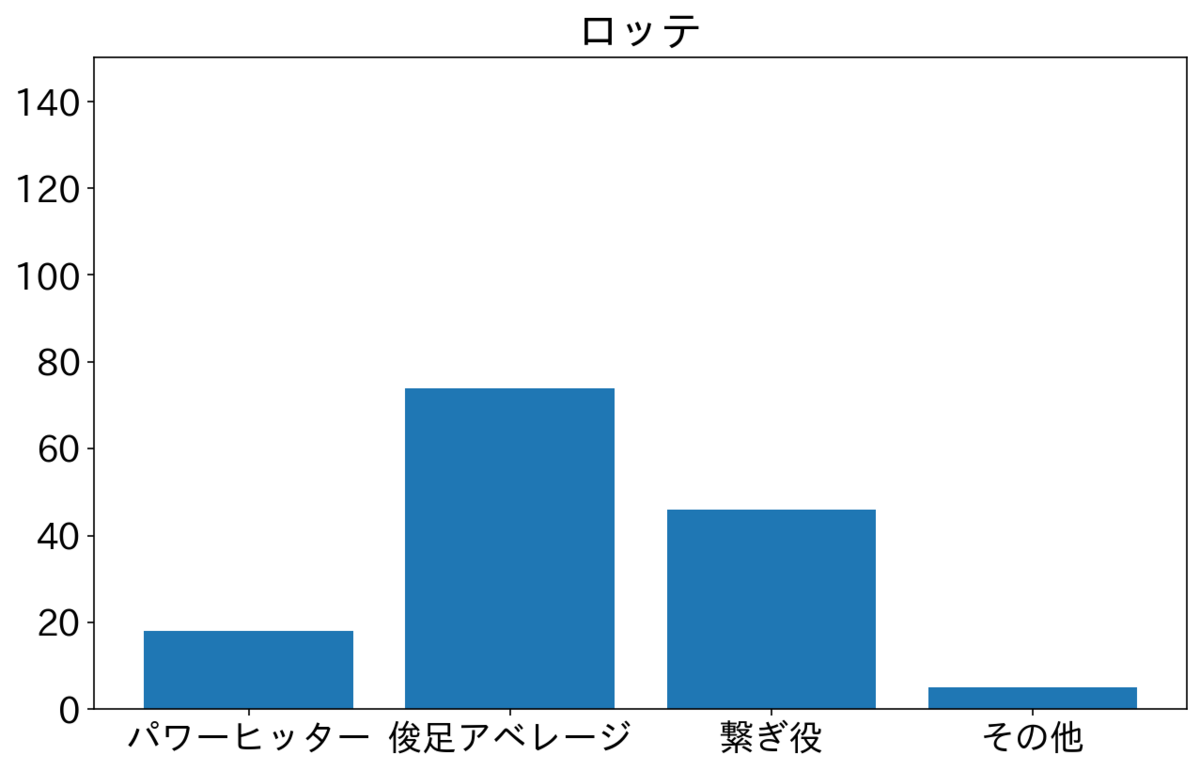
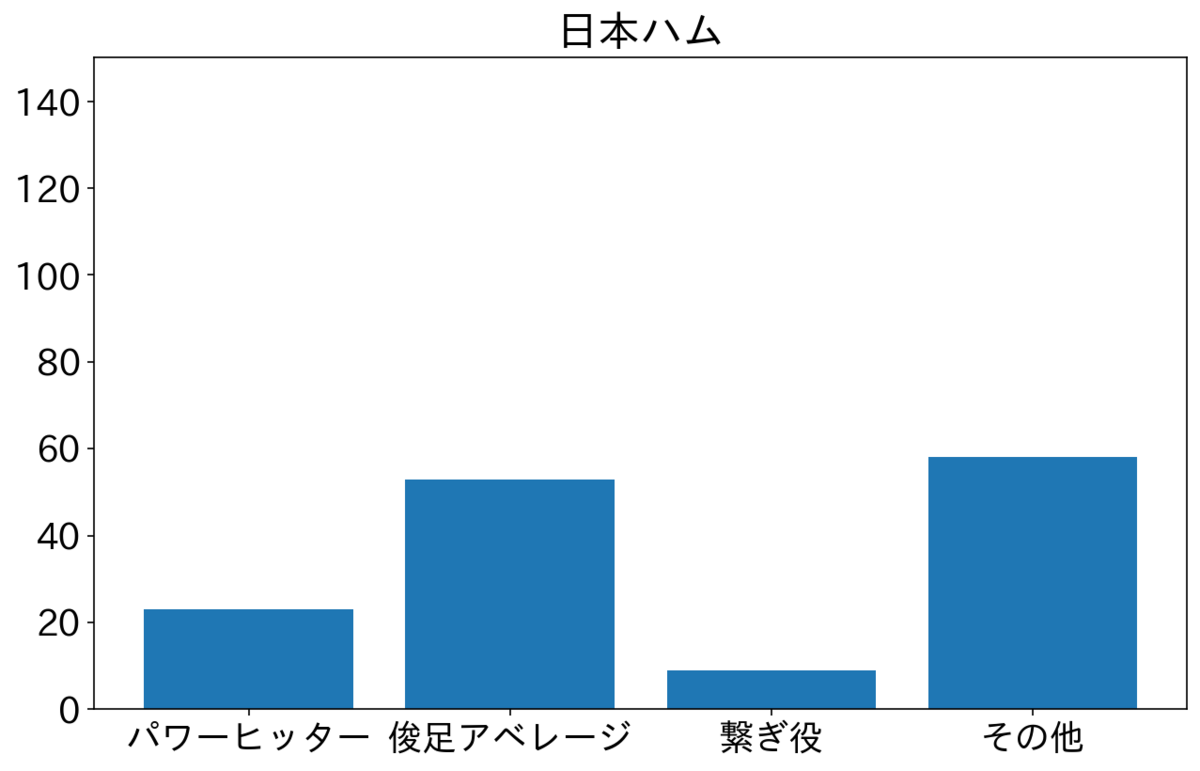
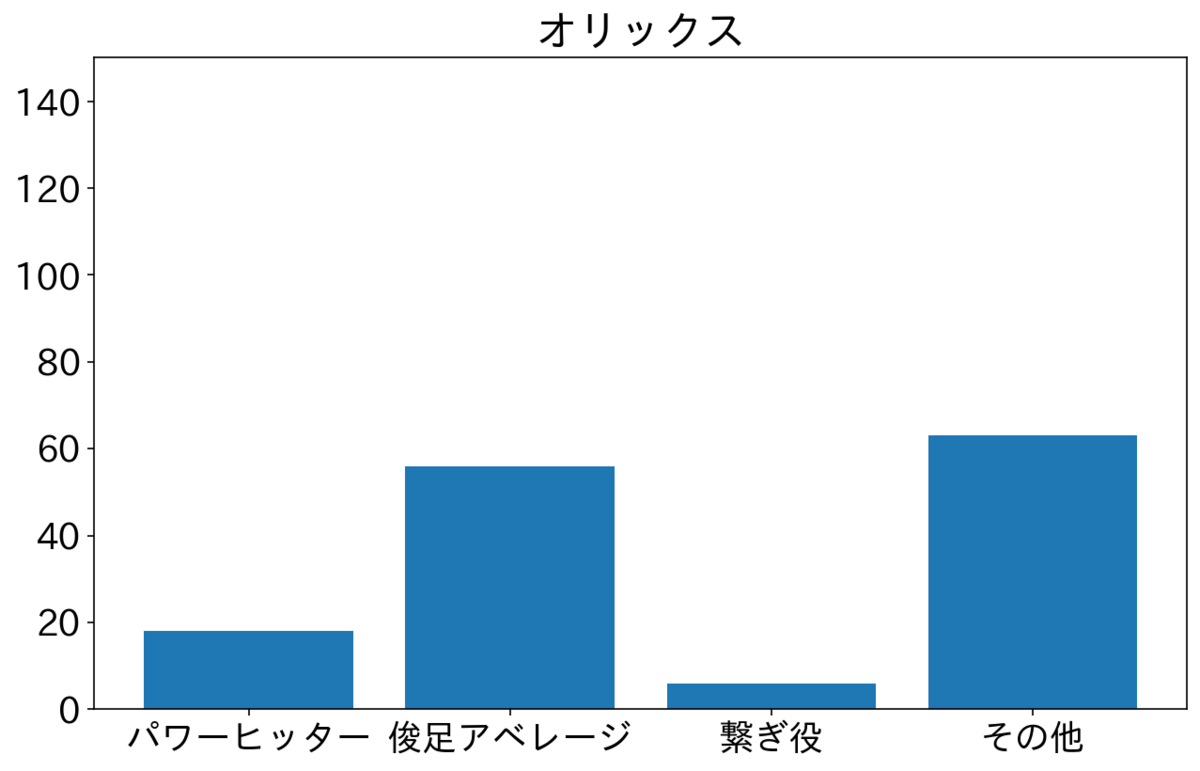
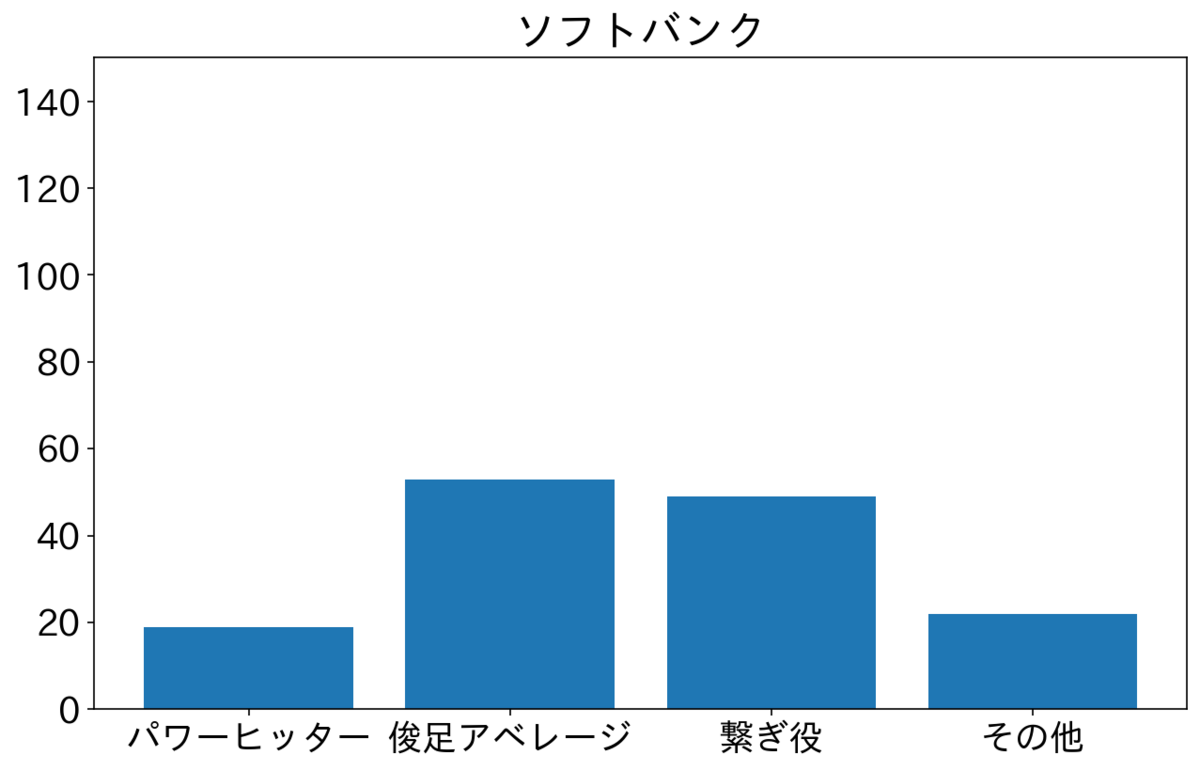
楽天・西武・ロッテが俊足アベレージを多く2番に置いている。特に楽天が俊足アベレージが多いが小深田選手が俊足アベレージタイプで73試合が2番スタメンだったためである。西武は源田選手が50試合、ロッテは藤岡選手が72試合2番でスタメンだった。2人とも俊足アベレージである。オリックスと日ハムはよく見ていないが、その他が多いので選手をいろいろ試しているのかもしれない。ソフトバンクは俊足アベレージと繋ぎ役が半分ずつで横浜と似てる。
【R言語】uniteを使った列の結合
unite関数は、データフレームの列を結合するための関数で、複数の列を結合して新しい列を作成することができます。
unite関数は、以下のような構文を持ちます。
unite(data, col, ..., sep = "_", remove = TRUE)
- data : データフレーム
- col : 新しい列名
- ... : 結合する列名
- sep : 区切り文字
- デフォルトでは「_」
- remove : 結合した列を削除するかどうか
- デフォルトでは削除する
パイプ演算子を用いたやり方では下記のように使います。
df %>% unite(col, ..., sep = "_", remove = TRUE)
第一引数がdata(data.frame)ではなくcol(新しい列名)になっています。
例
こちらのデータのうち和暦・給付年度・被災学校種の3列を用いて使用例を書いていきたいと思います。
先頭5行は下記のとおり
| 和暦 | 給付年度 | 被災学校種 |
|---|---|---|
| 平成 | 17 | 小 |
| 平成 | 17 | 小 |
| 平成 | 17 | 小 |
| 平成 | 17 | 小 |
| 平成 | 17 | 小 |
環境
ライブラリの読み込み
library(tidyverse) library(readxl)
データの読み込み
df <- read_excel("shougai_20230201.xlsx") %>% select(和暦, 給付年度, 被災学校種)
このデータフレームに対して、和暦列と 給付年度列を結合して新しい列和暦_ 給付年度を作成する場合は、以下のようにします。
df %>% unite(和暦_給付年度, 和暦, 給付年度) %>% head(5)
| 和暦_給付年度 | 被災学校種 |
|---|---|
| 平成_17 | 小 |
| 平成_17 | 小 |
| 平成_17 | 小 |
| 平成_17 | 小 |
| 平成_17 | 小 |
このコードでは、dfデータフレームの和暦列と 給付年度列を結合して新しい列和暦_ 給付年度を作成しています。結合に用いた2つの列は削除され新しい列ができています。
区切り文字を指定する
区切り文字はデフォルトではアンダースコア(_)が用いられます。指定したい場合はsepで指定します。
下記のコードでは区切り文字を半角( )を指定しています。
df %>% unite(和暦_給付年度, 和暦, 給付年度, sep = " ") %>% head(5)
| 和暦_給付年度 | 被災学校種 |
|---|---|
| 平成 17 | 小 |
| 平成 17 | 小 |
| 平成 17 | 小 |
| 平成 17 | 小 |
| 平成 17 | 小 |
区切り文字をなくしたい場合はsep=""とします。
df %>% unite(和暦_給付年度, 和暦, 給付年度, sep="") %>% head(5)
| 和暦_給付年度 | 被災学校種 |
|---|---|
| 平成17 | 小 |
| 平成17 | 小 |
| 平成17 | 小 |
| 平成17 | 小 |
| 平成17 | 小 |
結合に用いた列を残す
デフォルトでは結合に用いた列は残りません。結合に用いた2つの列を残したい場合は引数のremoveでFALSEを指定します。
df %>% unite(和暦_給付年度, 和暦, 給付年度, remove = FALSE) %>% head(5)
| 和暦_給付年度 | 和暦 | 給付年度 | 被災学校種 |
|---|---|---|---|
| 平成_17 | 平成 | 17 | 小 |
| 平成_17 | 平成 | 17 | 小 |
| 平成_17 | 平成 | 17 | 小 |
| 平成_17 | 平成 | 17 | 小 |
| 平成_17 | 平成 | 17 | 小 |
複数列を結合する
複数列を結合する場合は、結合したい列をカンマで区切って追加していきます。 下記のコードでは、和暦・給付年度・ 被災学校種の3列を用いて和暦給付年度被災学校種という列を作っています。
df %>% unite(和暦_給付年度_被災学校種, 和暦, 給付年度, 被災学校種) %>% head(5)
| 和暦_給付年度_被災学校種 |
|---|
| 平成_17_小 |
| 平成_17_小 |
| 平成_17_小 |
| 平成_17_小 |
| 平成_17_小 |